[facebook fastText] supervised classification 예제
1. fastText란?
- fastText is a library for efficient learning of word representations and sentence classification
2. 소스 위치 (github)
3. 빌드
- $ git clone https://github.com/facebookresearch/fastText.git
- $ cd fastText
- $ make
4. 예제 실행
- $ git clone https://github.com/facebookresearch/fastText.git
- $ cd fastText
- $ ./classification-example.sh
4-1. 테스트 환경 준비
- https://raw.githubusercontent.com/le-scientifique/torchDatasets/master/dbpedia_csv.tar.gz 를 다운로드
- The DBpedia ontology classification dataset is constructed by picking 14 non-overlapping classes from DBpedia 2014.
- They are listed in classes.txt. From each of thse 14 ontology classes, we randomly choose 40,000 training samples and 5,000 testing samples. Therefore, the total size of the training dataset is 560,000 and testing dataset 70,000.
- The files train.csv and test.csv contain all the training samples as comma-sparated values. There are 3 columns in them, corresponding to class index (1 to 14), title and content. The title and content are escaped using double quotes ("), and any internal double quote is escaped by 2 double quotes (""). There are no new lines in title or content.
- data/dbpedia_csv.tar.gz 로 저장 후 압축 풀기
- data/dbpedia_csv/train.csv 를 data/dbpedia.train 로 normalize한 뒤 각 행을 랜덤하게 뒤섞어서 저장
- 예를 들면 train.csv의 첫 라인을 506836 라인으로
- 1,"E. D. Abbott Ltd"," Abbott of Farnham E D Abbott Limited was a British coachbuilding business based in Farnham Surrey trading under that name from 1929. A major part of their output was under sub-contract to motor vehicle manufacturers. Their business closed in 1972."
- __label__1 , e . d . abbott ltd , abbott of farnham e d abbott limited was a british coachbuilding business based in farnham surrey trading under that name from 1929 . a major part of their output was under sub-contract to motor vehicle manufacturers . their business closed in 1972
- data/dbpedia_csv/test.csv 를 data/dbpedia.test 로 normalize해서 저장
4-2. Train
$ ./fasttext supervised -input "data/dbpedia.train" -output "result/dbpedia" -dim 10 -lr 0.1 -wordNgrams 2 -minCount 1 -bucket 10000000 -epoch 5 -thread 4- supervised train a supervised classifier
- -dim size of word vectors [100]
- -lr learning rate [0.1]
- -wordNgrams max length of word ngram [1]
- -minCount minimal number of word occurences [1]
- -bucket number of buckets [2000000]
- -epoch number of epochs [5]
- -thread number of threads [12]
4-3. 테스트
$ ./fasttext test "result/dbpedia.bin" "data/dbpedia.test"
P@1: 0.985
R@1: 0.985
Number of examples: 70000
4-4. 예측
$./fasttext predict "result/dbpedia.bin" "data/dbpedia.test" > "result/dbpedia.test.predict"
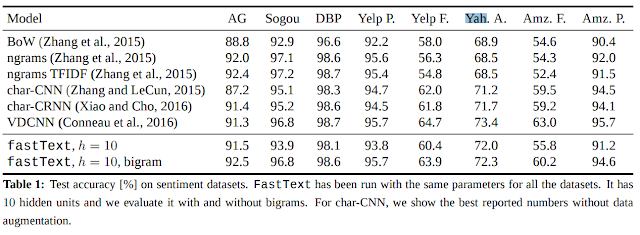
5. 알고리즘 페이퍼
- Bag of Tricks for Efficient Text Classification
- 페이퍼의 fastText 벤치마크 결과


댓글
댓글 쓰기